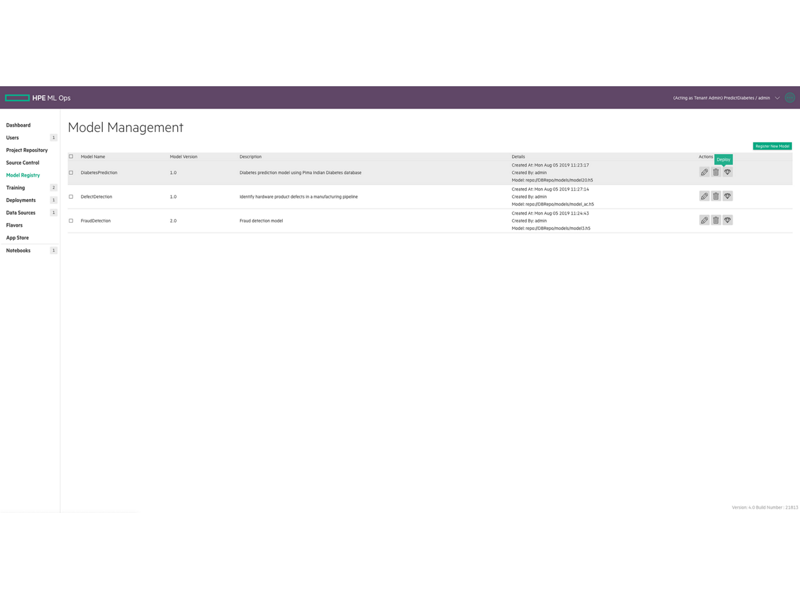
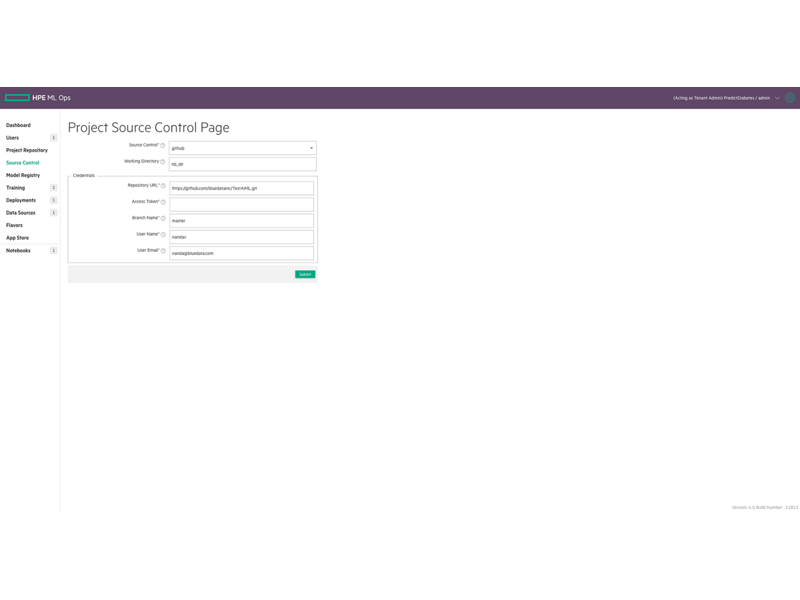
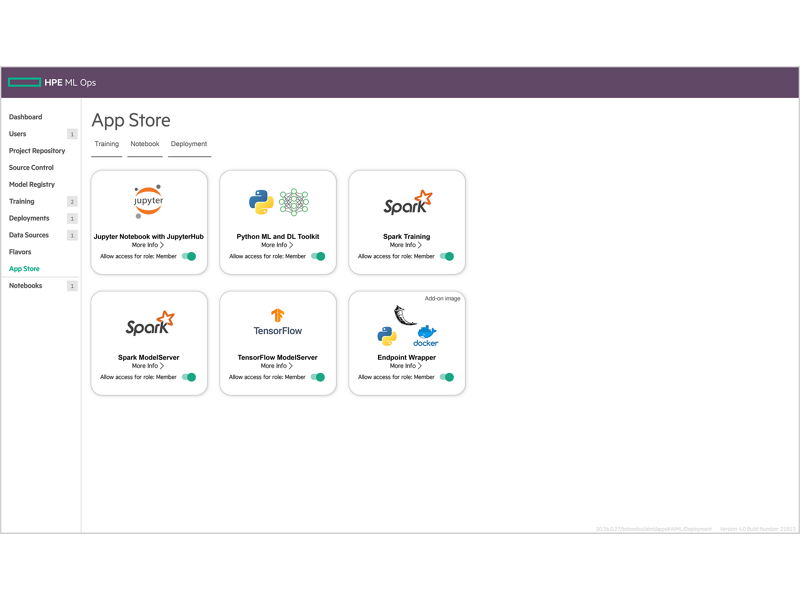

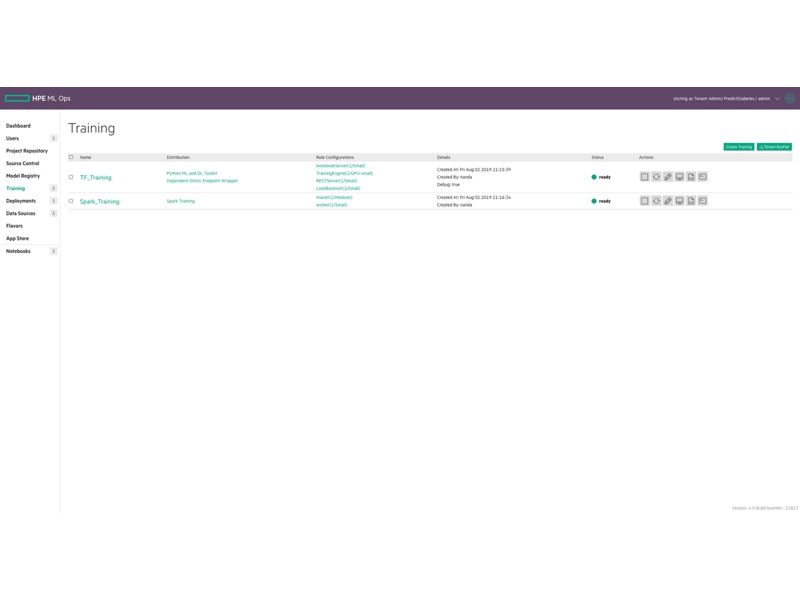
이전 DevOps 소프트웨어 개발과 마찬가지로 데이터 과학 조직은 프로젝트를 개발 단계에서 생산 단계로 진행시킬 때 여전히 많은 시간과 노력을 들입니다. 모델 버전 관리 및 코드 공유가 수동으로 진행되고, 툴과 프레임워크의 표준화가 부족해 기계 학습 모델을 상품화하는 과정이 번거롭고 시간이 많이 걸립니다.
HPE Ezmeral ML Ops(HPE Ezmeral Machine Learning Ops)는 HPE Ezmeral Runtime Enterprise의 기능을 확장하고 엔터프라이즈 기계 학습에 DevOps 같은 민첩성을 제공합니다.
엔터프라이즈는 HPE Ezmeral ML Ops를 사용하여 DevOps 프로세스를 구현하고 ML 워크플로우를 표준화할 수 있습니다. HPE Ezmeral ML Ops는 데이터 과학팀에 온프레미스, 다중 퍼블릭 클라우드 또는 하이브리드 모델에서 기계 학습 또는 DL(딥 러닝) 워크로드를 유연하게 실행하고, 다양한 사용 사례에서 동적인 비즈니스 요건에 대응할 수 있는 엔드 투 엔드 데이터 과학 요구 사항에 적합한 플랫폼을 제공합니다.
새로운 기능
- KubeFlow 1.3(보안 강화)? 및 모델 모니터링
- Spark Operator Add-on, Spark History Server, Spark Thrift Server, Apache Livy 및 Hive Metastore
- Delta Lake 지원
- 지원되는 Spark 버전: Apache Spark 2.4.7 및 Apache Spark 3.1.2
- Apache Spark용 HPE Ezmeral 런타임 분석
- HPE Ezmeral Runtime Enterprise 새로운 UI 소개, ?향상된 UX: 데이터 과학자를 위한 향상된 UX?, 간소화된 코딩 경험을 위한 패키지 라이브러리 및 KubeFlow용 Notebook Magics
특징
더 빨라진 가치 실현
직관적인 그래픽 사용자 인터페이스를 통해 인프라 관리 및 프로비저닝이 가능합니다.
며칠이 아닌 몇 분 만에 환경의 개발 프로비저닝, 테스트 또는 프로덕션이 가능합니다.
사일로화된 개발 환경을 생성하지 않고 원하는 툴과 언어로 새로운 데이터 과학자를 신속하게 온보딩할 수 있습니다.
생산성 향상
데이터 과학자는 교육 작업 완료를 대기하는 것보다 모델 구축 및 결과 분석에 시간을 활용합니다.
HPE Ezmeral Runtime Enterprise는 다중 테넌트 환경에서 정확성 손실이나 성능 저하를 방지할 수 있습니다.
공유 코드, 프로젝트, 모델 리포지토리로 협업과 복제가 강화됩니다.
위험 완화
컴퓨팅과 데이터에 엔터프라이즈 등급 보안 및 액세스 제어를 제공합니다.
계열 추적으로 규제 준수에 대한 모델 거버넌스 및 감사 가능성을 제공합니다.
타사 소프트웨어와의 통합으로 해석 가능성을 제공합니다.
고가용성 배포로 크리티컬 애플리케이션의 성공적인 실행을 보장합니다.
유연성 및 탄력성
비즈니스 요구 사항에 적합하게 온프레미스, 클라우드 또는 하이브리드 모델에 배포 가능합니다.
클러스터의 자동 확장으로 동적 워크로드의 요구 사항을 처리합니다.
- Kubernetes®는 미국 및 기타 국가에서 Linux Foundation의 등록된 상표이며 Linux Foundation의 라이선스에 따라 사용됩니다. LINUX FOUNDATION 및 YOCTO PROJECT는 Linux Foundation의 등록된 상표입니다.